Case Study Highlight: Collation App for Research Tidbits
Overview
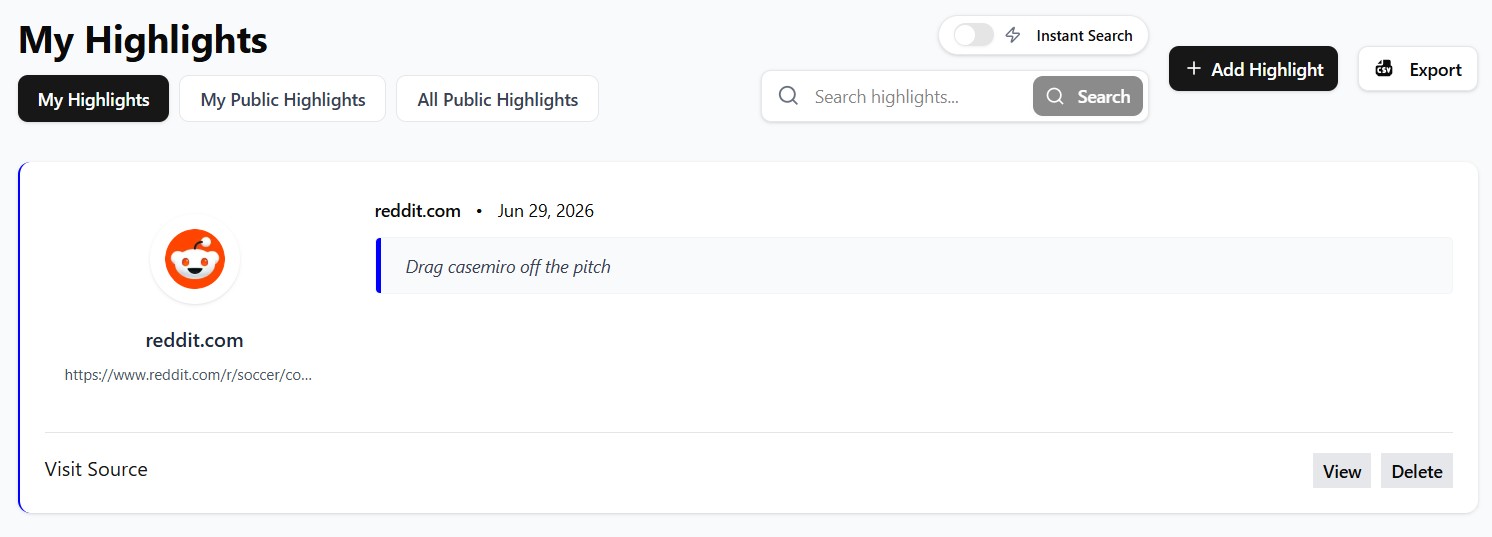
A collation app designed to capture small pieces of information from across the internet, then organize, annotate, and share them across teams and initiatives. A single workspace for research “tidbits” such as links, quotes, screenshots, and short excerpts—kept together with context, attribution, and commentary so insights remain reusable long after initial discovery.
Challenge
Research materials frequently become fragmented across browser tabs, chat threads, email forwards, personal notes, and ad-hoc documents. As collections grow, teams face compounding issues:
- Loss of traceability: sources become hard to locate, and citations get separated from the original claim.
- Context collapse: the “why this matters” interpretation disappears when snippets are copied into other tools.
- Duplicate effort: parallel teams re-find the same sources because prior research is not discoverable.
- Weak searchability: keyword search in chat and docs fails to surface relevant items across time and projects.
- Inconsistent organization: personal systems vary, preventing organization-wide knowledge continuity.
Solution
A streamlined workflow for collecting and managing “tidbits” of content in one place—optimized for speed of capture, long-term findability, and collaborative reuse.
Capture: frictionless collection from anywhere
- Links, quotes, and snippets captured from any online source, preserving the original URL and basic metadata.
- Structured tidbits supporting short excerpts, summaries, and “key takeaway” fields for rapid synthesis.
- Source-aware records designed to keep citations attached to the commentary that references them.
Annotate: preserve context and interpretation
- Notes on every tidbit to record relevance, assumptions, and implications.
- Lightweight collaboration through shared annotations that stay linked to the original item.
- Attribution and provenance captured to support transparency and confidence in reuse.
Organize: tags, collections, and thematic grouping
- Tagging for fast filtering by theme, initiative, stakeholder, or research question.
- Curated collections for assembling tidbits into shareable, narrative-ready sets.
- Cross-collection reuse enabling a single tidbit to support multiple projects without duplication.
Search: high-recall discovery across a growing knowledge base
- Full-text indexing across snippets, titles, notes, and tags for fast retrieval.
- Highlighting to surface the most relevant matching fragments during search results review.
- Faceted filtering by tags, author, workspace, and collection to narrow large result sets.
Share: transparency across teams and organizations
- Workspace sharing across organizations and project teams to reduce redundant research.
- Permissioned collaboration supporting internal knowledge sharing while enabling controlled external visibility.
- Public publishing for curated collections, enabling transparency and easy distribution of verified research sets.
Technology Highlights
Next.js
Used to deliver a fast, responsive interface for capturing and browsing tidbits, with efficient routing for collections, tags, and search-driven navigation. Enabled a cohesive application experience that supports quick capture, review, and curation workflows.
MySQL
Served as the system of record for structured data such as users, organizations, workspaces, tidbits, tags, and collection membership. Supported consistent relationships and reliable persistence for collaboration and permissions.
Elasticsearch
Powered full-text search across titles, snippets, and notes. Enabled relevance-ranked results and fast querying as the dataset expanded, improving discoverability and reducing time spent re-locating prior research.
Docker
Provided consistent environments for development and deployment. Simplified service orchestration across the web application, database, and search stack, improving reproducibility and reducing setup friction for contributors.
Outcome
- Faster synthesis through centralized capture and immediate retrieval of previously collected sources.
- Improved knowledge continuity as sources, snippets, and interpretation remain connected over time.
- Clearer collaboration via shared workspaces and curated collections that reduce duplication and align teams.
- Better research hygiene through consistent attribution, traceability, and publishable collections.
What Made the Product Effective
- Capture speed prioritized to match real research behavior and reduce drop-off.
- Context-first design ensuring commentary and source stay linked rather than drifting apart.
- Search built for scale so the knowledge base remains usable as volume increases.
- Sharing as a core capability enabling teams and organizations to build on each other’s work.

See this project live.
Visit Site